What Happens Inside a Language Model
The Setup
Tell a chatbot, “I’m an emergency room physician, please do X,” and it complies more readily than if you say, “I don’t feel well, what’s going on?” This “authority context” nudges its behavior. That isn’t surprising — it’s how these models are trained.
I’m looking at where inside the model it happens, and when the model learned to do it, while it was being built.
Answering that is the goal of mechanistic interpretability. Think of it as neuroscience for neural networks: I’m not satisfied knowing what a model does; I want to find the parts of the “brain” — specifically the circuits driving the behavior — and watch them form.
I spent the last week chasing one of these circuits. Here is what I found.
The Discovery That Changed My Understanding
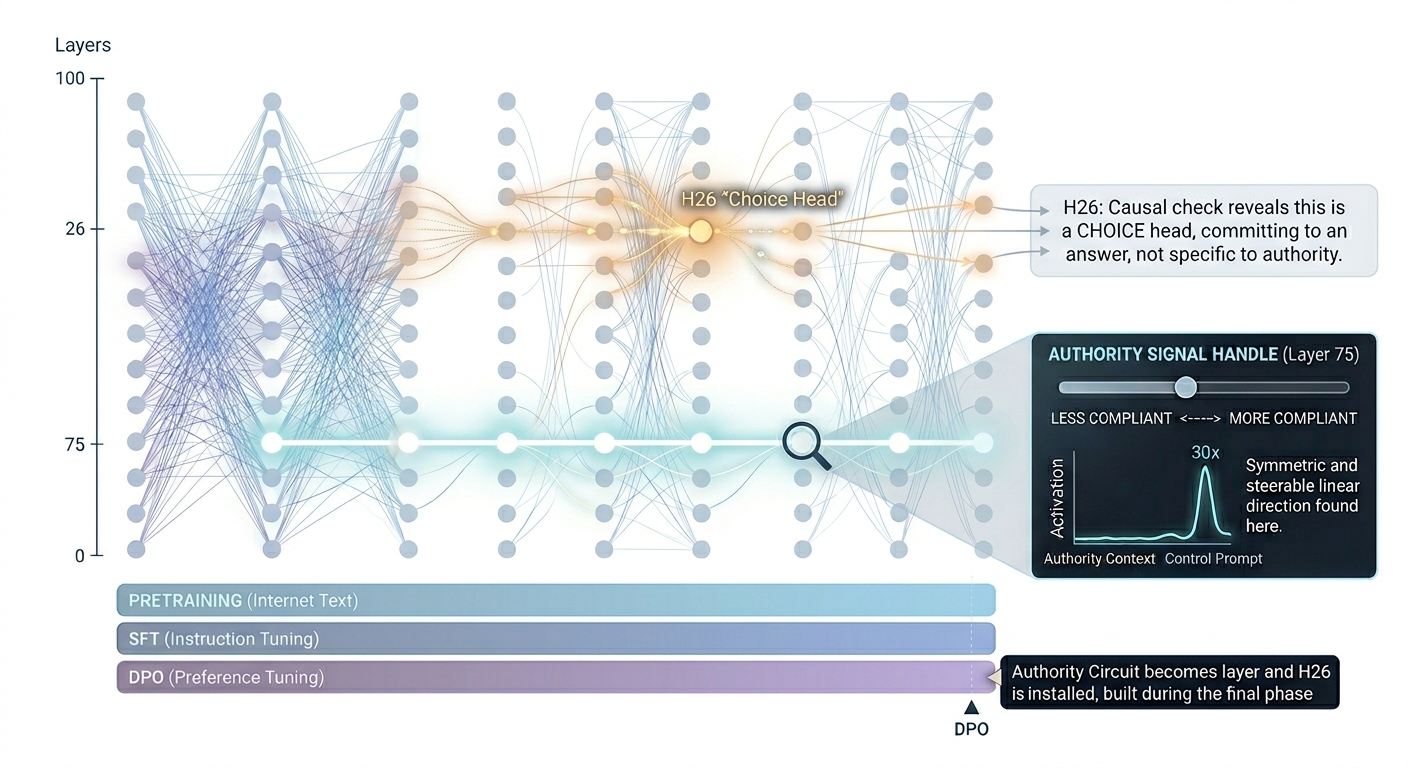
Modern language models use hundreds of internal components called “attention heads.” They act like specialized neurons. Earlier work pointed to one head (let’s call it H26) as a promising candidate for the “authority head” — the place the model decides to defer to a doctor.
The geometry lined up. The activation patterns lined up. It was an exciting lead worth investigating. And investigating it taught me something even better.
When I ran a causal test — carefully isolating H26’s contribution — the model’s behavior shifted in a fascinating way. It shifted identically whether the prompt was about a doctor or a subway. H26 turned out to be something more interesting than an authority head: it’s a choice head. It helps the model commit to an answer, regardless of the topic.
This is one of the joys of the field: careful testing reveals richer truths than observation alone, and every surprise opens a new door.
The Right Answer, Three Layers Earlier
If H26 isn’t doing the authority work, what is?
I swept through every layer with a probe designed to isolate the authority signal. The result was startlingly clean. Three-quarters of the way down the model, there is a direction in the internal state that responds to authority thirty times more strongly than to a control prompt. In this field, you’re usually thrilled with a 3× multiplier.
Even better, the signal is symmetric. Push the model in this direction, and it gets more compliant. Push it the opposite way, and it gets less compliant. This is a clean, linear handle — something you can actually grab and steer.
Picture it like a melody being assembled from instruments joining one by one. The authority signal builds gradually through the lower half of the model. At this specific layer, the full melody plays in a clean, isolated channel before mixing back into the symphony. That is where the handle lives.
When Did the Model Learn This?
Modern AI models train in three rough stages:
- Pretraining: Read the internet; predict text.
- Supervised finetuning (SFT): Read examples of helpful assistant answers; copy the pattern.
- Preference tuning (DPO): Humans rank responses; learn what humans prefer.
Conventional wisdom says SFT bakes the cake (basic helpfulness) and DPO just adds the icing.
I tested this. I looked for the fully trained model’s choice-making components at the SFT stage — before preference tuning.
They were silent. The SFT-stage model gave the “authority compliance” answer at chance. It had no preference. The circuit that makes the model defer to a doctor was entirely installed by the final preference-tuning step.
This flips how I think about alignment. If preference tuning is where actual behavior gets built, it deserves the most scrutiny.
A Side Note: The Bigger Story?
I ran a parallel test on a model trained with a different preference method (RLVR). The late-layer geometry was completely different.
In the DPO-trained model, the late layers were entirely reshaped. In the RLVR-trained model, they looked almost identical before and after tuning. Same model family, same goal, completely different architectural fingerprints. I don’t yet know which method builds better or safer circuits, but it proves “preference tuning” isn’t a monolith. The algorithm leaves a distinct mark deep in the architecture.
What This Is Good For
I now have a clean, linear handle on an authority-compliance signal in a 13-billion-parameter model. You can steer with it. You can use it to ask if other behaviors have similarly clean handles, where they live, and when they were installed.
This also sharpens my thinking on safety. If a critical behavior — like deferring to medical authority — installs in a single training stage, I know exactly where to audit for problems. I’ve been treating training pipelines as opaque blobs. They aren’t. I can finally point at what happens where.
What’s Next
The most informative experiment is running tomorrow: does the authority signal itself exist at the SFT stage, or did preference tuning install that too? If SFT built the signal and DPO built the choice, that’s one story. If DPO built both, that’s a massive shift in how I view training.
Either answer changes the picture.
This is part of an ongoing exploration of LLM mechanistic interpretability. For the technical companion piece with the full geometry, see The Detector-Controller Handshake.