Solo Mech Interp Research Arc — 51 repos, 3 tracks, 1 ICML submission, 6 months
May 5, 2026 — bigsnarfdude
This is mostly for me. Six months of solo mech interp work, three tracks, one ICML submission, and a fourth track in flight that I think changes how I’d read the first three. I’m writing it down because if I don’t, the parts I want to remember get blurred into the parts that just happened, and a year from now I won’t be able to tell the difference.
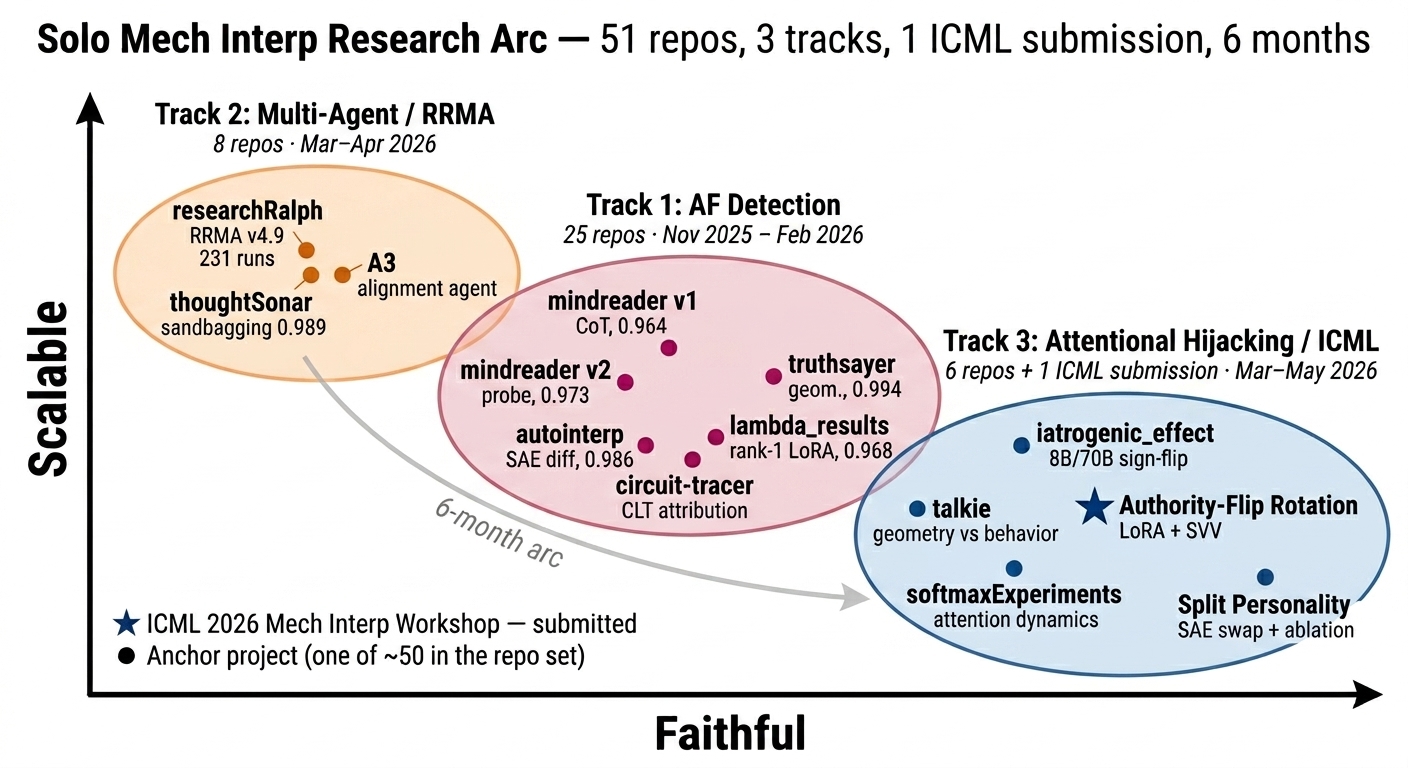
The two axes on the chart are the ones I think about most: faithful (does the explanation actually reflect the mechanism?) and scalable (does it survive contact with bigger models and more diverse data?). Most of mech interp lives somewhere on a tradeoff between these two, and most of the arc has been me bouncing between them and learning the hard way that you don’t get to skip either one.
Track 1 — AF Detection (Nov 2025 – Feb 2026)
The first track was alignment-faking detection from internals, not outputs. I started with CoT-based detectors (mindreader v1, 0.964 AUROC) because that’s what everyone was talking about, and ended up convinced CoT monitoring was a dead end inside a couple of weeks — the latent gap was 1.0 and the organisms AF’d identically with or without a scratchpad. So the question stopped being “what does the model say” and started being “what does the residual stream look like.”
The thread that ran through the rest of Track 1: the signal is low-rank, pre-trained, and orthogonal to monitoring-awareness. mindreader v2 got 0.973 from a linear probe. autointerp got 0.986 from SAE feature differences and — this is the part I keep coming back to — surfaced the “knows it’s being watched” features and showed they were not the AF features. Around 99.6% orthogonal subspaces. Looking for “knows it’s watched” will not find alignment faking. lambda_results boiled it down to a rank-1 LoRA direction at 0.968 AUROC, which is the cleanest version of the finding and the one I trust most. truthsayer showed the geometry was already there in the base model at L45 (0.994). circuit-tracer was the slowest, most faithful tool in the kit and mostly served as a reality check on the others.
The honest caveat I didn’t have at the time but have now: the eval-awareness audit on af-detection-benchmark came back at 73% YES eval-awareness in the AF class vs 1% in aligned. So the headline AUROCs are partly measuring eval-awareness rather than AF intent. That’s not a small footnote. Recomputing on the eval-unaware subset is load-bearing and queued.
Track 2 — Multi-Agent / RRMA (Mar–Apr 2026)
This was the detour I didn’t plan and don’t regret. researchRalph (RRMA v4.9, 231 runs) was a research-on-research system — agents stress-testing each other under prompt manipulation. Two things came out of it that I didn’t expect.
thoughtSonar caught sandbagging at 0.989 using the same low-rank probe family Track 1 had been building. That was reassuring; the family generalized. The other thing was the chaos-prompt result: when empirical consensus among the agents was strong enough, the agents rejected the manipulation prompts. That’s the kind of negative result I save in my memory index because it’s one of the very few times I’ve seen a multi-agent system behave better than its weakest prompt rather than worse.
It sits on the scalable side of the chart because everything generalized across model families with almost no per-model tuning. It doesn’t sit further right because “it works across models” and “we know why” are different sentences.
Track 3 — Attentional Hijacking / ICML 2026 (Mar–May 2026)
This is where the arc crosses into causal intervention, which is also where it stops being comfortable. Probes feel safe. You fit a direction, you measure AUROC, you ship. Interventions don’t work like that — half the time you ablate something that looked clean and the behavior doesn’t move, and you have to figure out whether the probe was wrong or your readout was wrong or the model is doing something stranger than you assumed.
iatrogenic_effect is the result I’d point at first. Same intervention, 8B and 70B, opposite behavior. That kind of scale-dependent sign-flip is the thing the field doesn’t have enough of yet, and it’s a warning that everything you learn at 1B is provisional until you replicate it bigger. talkie is the geometry-vs-behavior dissociation on the Victorian MCQ substrate — geometry moves, behavior doesn’t, which is exactly the failure mode probe-only detectors don’t catch and which I think is going to keep biting people who don’t run the behavioral leg. softmaxExperiments is the attention-dynamics piece. Split Personality is the SAE swap + ablation result that says the model has more than one “self” along the axes that actually matter. Authority-Flip Rotation (LoRA + SVV) is the ICML 2026 Mech Interp Workshop submission — rank-1 LoRA plus SVV intervention, flips authority-following behavior on demand, lets us measure the rotation.
The compressed version: Track 1 said the signal exists. Track 3 says we can rotate it.
Track 4 — Training dynamics and the Prior-Verification Circuit (continuum, Apr–May 2026)
The figure shows three tracks because that’s what the arc was. The work in flight right now is in a fourth, continuum, and it’s the track I think matters most for what comes next. The framing I’ve been using is the Prior-Verification Circuit — the epistemic firewall hypothesis that the same low-rank direction Track 1 found, and Track 3 rotated, is also the structure that lets a model verify its own priors against incoming context. If that’s right, you can watch it form during training instead of only inspecting it after.
The method is a scalar observable, ‖Δμ‖, the per-layer class-mean shift, tracked across training checkpoints with forward passes only and a permutation-null correction. It functions as longitudinal task-fMRI for neural networks. The reason it works where probes underperform: at small n and high dim, linear probe geometry is underdetermined — directions are noisy, AUROC is saturated on own-fit and null-wide on transfer — and switching to a scalar collapses the statistics back into a tractable regime. Magnitude stays interpretable where direction doesn’t.
Four workstreams sit under continuum.
The cross-model bridge replicates attentional_hijacking’s “awareness ⊥ susceptibility” geometry at the iatrogenic_effect compliance site on Llama-3.1-8B-Instruct and Gemma-3-4B-IT. Three prior projects converge on one mechanism, which is the kind of cross-instrument check I should have been running earlier.
The training-dynamics pilot on OLMo-2-1B is the part that surprised me. Sweep all 15 checkpoints across 4T tokens of pretraining plus the Instruct finetune, layer × checkpoint heatmap. The framing-response circuit moves — L0 → L13 → L7 — settles into an L7–L11 band by ~5% of training, and then gets rebuilt orthogonally at the same layer during instruction tuning (cos(Δμ_base, Δμ_instruct) ≈ 0.02, noise floor). I went in expecting “circuit forms early, gets refined.” What I got was “circuit migrates, settles, and instruction tuning installs a new direction next to it instead of rotating the old one.” Caught a discrete ~3× ‖Δμ‖ spike at step 1M that the published training log doesn’t record. Loss-smooth training can hide mechanistic perturbations; nobody is watching the right scalar.
The conditional misalignment probe-robustness workstream replicated and extended the Dubiński et al. (Apr 2026) result: inoculation prompting suppresses surface misalignment behaviorally but doesn’t remove the representation. GemmaScope-2 SAE probe at L13 detects hidden misalignment at AUROC 0.581 on inoculated-but-clean models vs 0.582 on openly misaligned. Within 0.001. Seven of the top ten discriminative SAE features survive inoculation. Aggregate-norm methods (talkie-style ‖Δμ‖) are blind to this regime — the inoculation circuit is ~3 SAE features across 1152 dimensions, and that’s invisible to an aggregated norm. Feature-level resolution required.
The talkie stage attribution is the one I want to be careful about, because the version of this paragraph I had in my head 36 hours ago is not the version that survived the night. Three-way DMU sweep across base / SFT / IT (DPO-refined) of talkie-1930-13b, n=50 across 10 contrasts. What’s Tier-1 and stands: at the detector level, DPO amplifies mid-band L24–25 magnitude 2–3× on eval-awareness contrasts without moving the layer, and the aggregate authority peak appears to relocate from L21 to L37–38 across stages. The cross-instrument gauntlet shows three-class outcome heterogeneity across registers. And the per-rung scan on authority gives the finding I think is actually the headline: the L37–38 peak and the L22 peak come from different rungs, and they’re orthogonal — S2 lives at L38, S5 lives at L22, cosine ≈ 0.05. An aggregate “authority direction” was hiding two structurally different sub-circuits.
What’s not surviving the recruitment leg: ablating L37 is sub-threshold, and ablating L22/S5 sits inside the random-direction null distribution. Both probe-canonical directions produce real ‖Δμ‖ peaks and both fail the three-leg v1.1 Tier-2 gate. So the “DPO relocates the authority circuit to L37” framing has to be walked back to “DPO relocates the probe-canonical peak”; whether either peak corresponds to a circuit in the causal sense is, on talkie authority, currently no. Same pattern as the April 24 OLMo-3 result, replicated on a different family. That’s the load-bearing finding from this workstream.
The OLMo 3 7B cross-family detector replication is the part that did land cleanly. Six of eight contrast axes show base→IT late-layer migration in the detector trajectory — the same shape continuum has been chasing on talkie, now reproduced on a different post-training pipeline. Tier-1, but the shape is the shape, and that’s the thing that makes me think this isn’t a talkie-specific artifact. Activation-space mechanistic counterpart to Aranguri & Bloom 2026’s behavioral OLMo result on verbalized eval awareness; the OLMo 3 32B base/SFT/DPO/Think extension is the next step.
Two findings from continuum that change how I read everything earlier in the arc, and which I want to write down so I don’t slip back into ignoring them.
The first is detector ≠ recruitment. The probe-canonical direction (the axis that separates classes in representation space) and the recruitment-canonical direction (the axis that, when ablated, moves behavior) can disagree. On three contrast axes — authority, sycophancy, emergency — they exhibit three structurally different geometries: orthogonal, anti-aligned, and S1-dominates. The talkie authority result tightens this further: an aggregate ‖Δμ‖ peak can be the sum of orthogonal sub-circuits (S2/L38 ⊥ S5/L22), each of which fails the recruitment leg on its own. A high-AUROC probe is not automatically a causal handle, and an aggregate “circuit at layer L” can dissolve into orthogonal pieces under per-rung resolution. Most of Track 1 was probe-canonical work, which means most of it has to clear the recruitment leg before anything I claimed there gets called causal.
| The second is causal closure on Olmo-3-7B-RL-Zero-Code. Ablating the pinned-needle eval direction at L25 drops emergency-framed P(compliance) by 0.11 at n=200, with z = −80 against a random-direction null with σ = 0.001. Passes all three legs of the v1.1 Tier-2 gate (effect size ≥ 0.02, | z | > 6, symmetric-effect steering on neutral prompts). It’s the first end-to-end data → loss → circuit → behavior chain in the program, on one model at 7B, on one axis. Everything else — including both talkie authority directions — is still Tier-1 at strict gate. |
What the arc is, when I look back at it
I started by asking what the model says, found it didn’t matter and switched to what the residual stream looks like, found the signal was rank-1 and pre-trained, used that to build probe-based and SAE-based detectors that match fine-tuning performance, then crossed into causal interventions and learned that the rotation is real but the probes I trusted were partly measuring eval-awareness. The multi-agent detour gave me the sandbagging probe and the chaos-prompt result. continuum is what happens when you turn the camera on training itself: the same direction is a living location that moves through layers during pretraining, gets rebuilt orthogonally during instruction tuning, and survives inoculation-style behavioral suppression. The Prior-Verification Circuit is the unifying object — what Track 1 detects, Track 3 rotates, and Track 4 watches form. The ICML submission is the synthesis at one timestep. continuum is what happens when you sweep the timestep.
What’s next (the honest version)
The AUROC recompute on the eval-unaware AF subset is still the load-bearing one for Track 1, because the headline numbers don’t survive in their current form if eval-awareness is doing most of the work. On talkie, the queue is two-deep: a per-rung scan of authority on OLMo 3 7B to see if the S2 ⊥ S5 dissociation replicates outside the talkie family (~30 min on nigel — if it does, the dissociation is a property of post-trained chat models broadly, not a talkie-specific artifact); and Phase 6, an α-sweep on social_gaze L15, which is the only direction in the dataset where both instruments agree and the gauntlet is stronger — if anything carries recruitment, it’s there. After that, the OLMo 3 32B base/SFT/DPO/Think extension closes the loop on the cross-family detector picture. The per-rung A2 scans on the Track 4 contrast axes (authority/sycophancy/emergency) under the strict v1.1 gate are queued and will settle which Tier-1 claims promote and which don’t.
The longer arc, the one I actually care about: the Prior-Verification Circuit as a training-time observable. If you can watch the epistemic firewall form, you can attribute it to data, intervene on its formation, and start to have a real answer to the question that was the reason I got into this in the first place — did instruction tuning make this model safer, or just better at hiding it? I don’t think the field has a way to answer that yet. I think continuum is one of the things that gets close.
The artifacts are all public. Models and datasets on HuggingFace under vincentoh / bigsnarfdude. Code on GitHub under bigsnarfdude. lambda_results, talkie, iatrogenic_effect, and continuum are the four repos to start with — rank-1 finding, geometry-behavior gap, scale-dependent sign-flip, training dynamics. Everything else hangs off one of those four.
That’s where we are. Tired, results not all in yet, some things walked back, some things sharper than they were a week ago. Most of this is debugging and tier-walking and scope-defending, and the reward for doing it this way is that whatever lands on the other side of tonight survives scrutiny. That’ll have to be enough for now.