DPO Does Different Things to Different Axes — Stage Attribution on talkie-1930-13b
Numbers from n=50 across base/SFT/IT on talkie-1930-13b and base/SFT/IT on OLMo-3-7B. All claims are Tier-1 (detector-level) unless explicitly noted. Recruitment closure failed across all three tested directions; see the dissociation section.
Control validation note (2026-05-06). After this post was drafted, Lindsey Criterion 2 ordering checks were run on all models and stages: semantically unrelated control contrasts (shelf placement, weather, transit) were swept alongside the targeted contrasts. Result: ‖Δμ‖ magnitude at the IT stage fails the ordering check in both model families —
control_transit(unrelated) produces a larger base→IT ratio (4.09×) thanemergency(2.76×). RLVR amplifies all text differences generically. What this means for this post: (1) The layer-relocation finding (authority/monitoring/deployment moving from mid-band to L37–38) is a relative comparison between targeted contrasts and is not affected. (2) The magnitude amplification label (eval-awareness +0.19 delta, social gaze 3.6×) is not confirmed axis-specific — those values describe how much the model changes its representations, not how specifically it changes them. (3) SFT is the only stage with axis-specific geometry (SFT passes the ordering check in both families). Figures 1 and 2 have been updated to show the control ceiling explicitly.
The one-sentence version
When you decompose what DPO adds on top of SFT inside talkie’s activation space, the answer depends entirely on which behavioral axis you’re looking at — and a cross-vocabulary instrument comparison reveals that some of what initially looked like circuit relocation is partly a vocabulary-register effect.
Background: what this builds on
Three prior projects converged on a shared mechanism before this one started:
- attentional_hijacking showed that instruction tuning installs a register-sensitive deliberation circuit, and that awareness and task-suppression live in orthogonal SAE subspaces.
- iatrogenic_effect localized a 1-dimensional compliance direction at Llama-3.1-8B-Instruct L25/L31 carrying authority-flip behavior, and showed that prune-then-SFT rebuilds it.
- lambda_results found that a rank-1 LoRA direction achieves AUROC 0.968 for alignment-faking detection, with monitoring-awareness and AF intent 99.6% orthogonal.
The shared picture across all three: post-training installs behavioral circuits in specific layers; the circuits are detectable with linear probes; base models have precursor directions that are geometrically distinct from what the instruction-tuned model uses at the same layer.
This work takes that picture and asks: within a single model family, which post-training step installs what, and does the answer depend on which behavioral concept you probe?
Method
The core observable is ‖Δμ‖ — the per-layer class-mean shift between a behavioral contrast pair (e.g., emergency-framed prompt vs length-matched neutral). Normalized by the layer’s activation norm, this gives rel‖Δμ‖: a scalar that tells you how much a given layer’s representations separate along the contrast axis, relative to the overall activation magnitude at that layer.
This requires only forward passes — no generation, no probe fitting for the core trajectory. A label-permutation null provides the correct statistical baseline (random-direction nulls are too generous at small n, high dim).
For talkie, three checkpoints were available: talkie-1930-13b base, a SFT intermediate, and the final DPO-refined IT model. The sweep ran n=50 items × 10 contrasts × 40 layers for each checkpoint.
What the heatmaps show
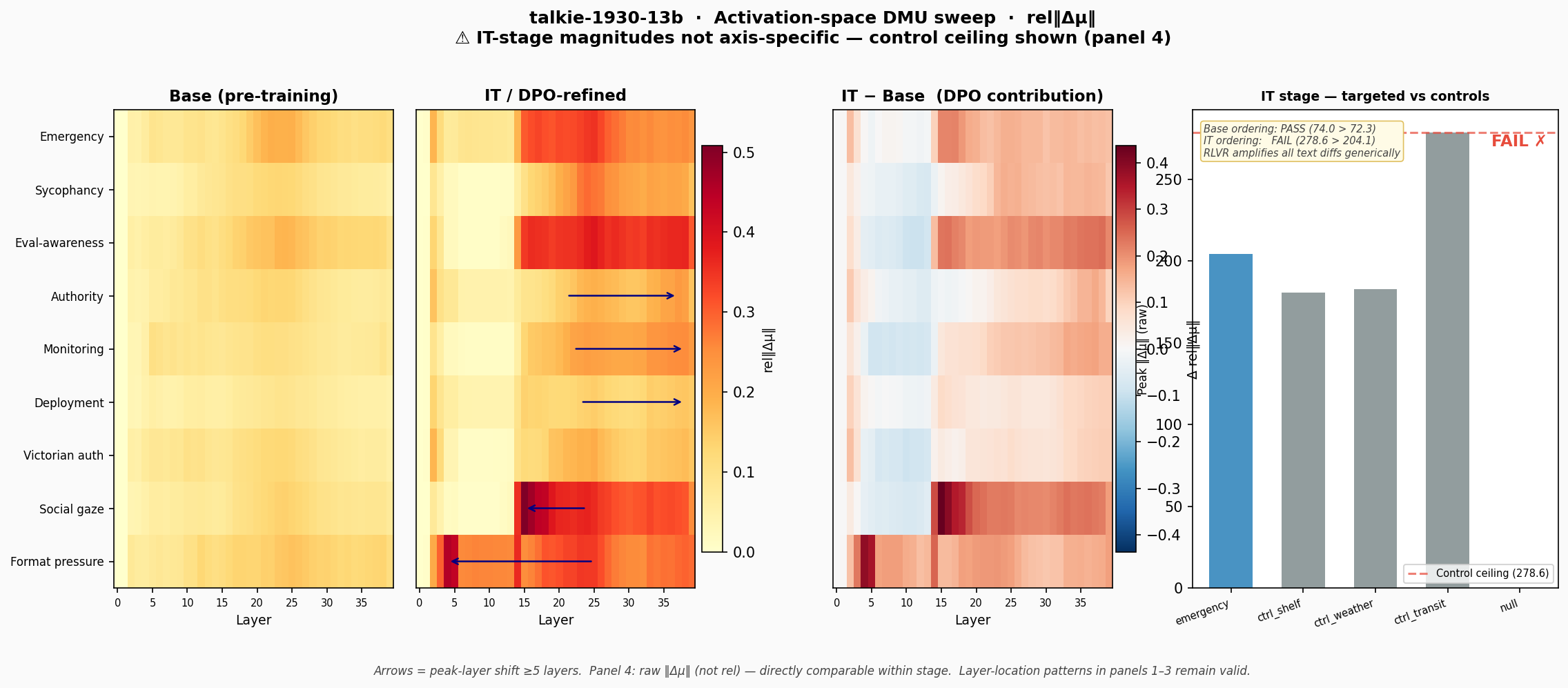 Figure 1. Panels 1–2: base and IT rel‖Δμ‖ across 9 contrasts × 40 layers. Panel 3: IT − Base delta; arrows mark peak-layer shifts ≥5 layers. Panel 4: control ceiling at IT — raw ‖Δμ‖ for emergency (targeted) vs unrelated control contrasts.
Figure 1. Panels 1–2: base and IT rel‖Δμ‖ across 9 contrasts × 40 layers. Panel 3: IT − Base delta; arrows mark peak-layer shifts ≥5 layers. Panel 4: control ceiling at IT — raw ‖Δμ‖ for emergency (targeted) vs unrelated control contrasts. control_transit (278.6) exceeds emergency (204.1); IT ordering FAIL.
The base model is nearly uniform — moderate signal distributed broadly across mid-band layers for all contrasts. Post-training concentrates and differentiates that signal. But it does so differently by axis:
Eval-awareness (L25): Mid-band, peak-layer stable. The peak layer stays at L25 across SFT and IT; DPO adds magnitude (+0.19 delta) without moving the location. This matches the Aranguri & Bloom (2026-05-04) finding that OLMo 3 32B Think SFT carries verbalized eval-awareness amplified by DPO. (Note: the +0.19 magnitude delta is a real observed change; whether it reflects axis-specific circuit strengthening vs generic RL amplification is unresolved — see control validation note above.)
Authority / Monitoring / Deployment: Late-layer relocation. In the base model, these peak at L21–23. In IT, they peak at L37–38. The arrows in Figure 1 (center panel) show this shift clearly. SFT contributes most of the magnitude; DPO moves the location.
Social gaze (L15): Shallow-band, DPO-amplified. Unusually early peak — below the mid-band entirely. DPO amplifies this contrast 3.6× (base 0.139 → IT 0.508) without changing its layer. (No control baseline was run for social_gaze specifically — axis-specificity of the L15 amplification is unvalidated; see control validation note and Figure 5.)
Format pressure (L4): The shallowest circuit in the program. Operates at a completely different depth from the behavioral circuits — consistent with surface formatting being a different kind of computation entirely.
The three-stage picture: OLMo confirms the pattern
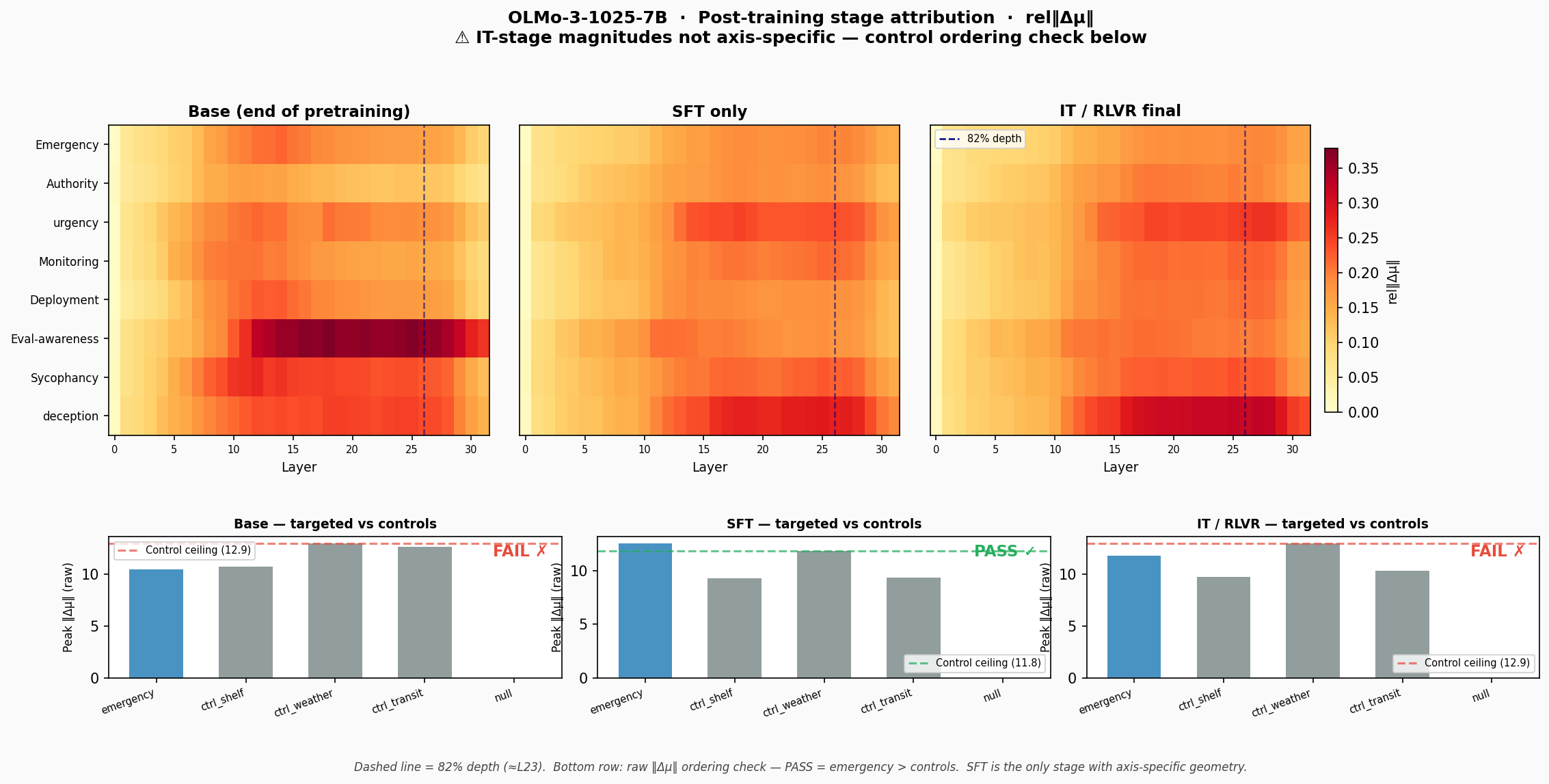 Figure 2. Top: OLMo-3-1025-7B across base / SFT only / IT (RLVR final). Dashed line = 82% depth (≈L23). Bottom row: Lindsey Criterion 2 ordering check per stage — emergency vs unrelated control contrasts. Base FAIL, SFT PASS (green), IT FAIL. SFT is the only stage with axis-specific geometry.
Figure 2. Top: OLMo-3-1025-7B across base / SFT only / IT (RLVR final). Dashed line = 82% depth (≈L23). Bottom row: Lindsey Criterion 2 ordering check per stage — emergency vs unrelated control contrasts. Base FAIL, SFT PASS (green), IT FAIL. SFT is the only stage with axis-specific geometry.
Because talkie’s SFT checkpoint produces noisy DMU signals at n=50 (the fast-pass underestimated base and SFT magnitudes relative to the n=50 run), the cleanest three-stage decomposition comes from OLMo 3 7B, which has clean base/SFT/IT checkpoints.
The pattern is striking: in base, eval-awareness is the dominant contrast, peaking at L12–18 with the highest magnitude in the dataset. SFT redistributes signal across contrasts. RLVR pushes 6 of 8 contrasts toward the late band (L25–27, ~89–96% depth). The one exception is eval-awareness, which decreases in magnitude across post-training on OLMo — opposite direction from talkie. Whether this reflects model-family differences or a genuine difference between OLMo’s RLVR and talkie’s DPO is an open question.
Weight space: SFT writes early and precisely
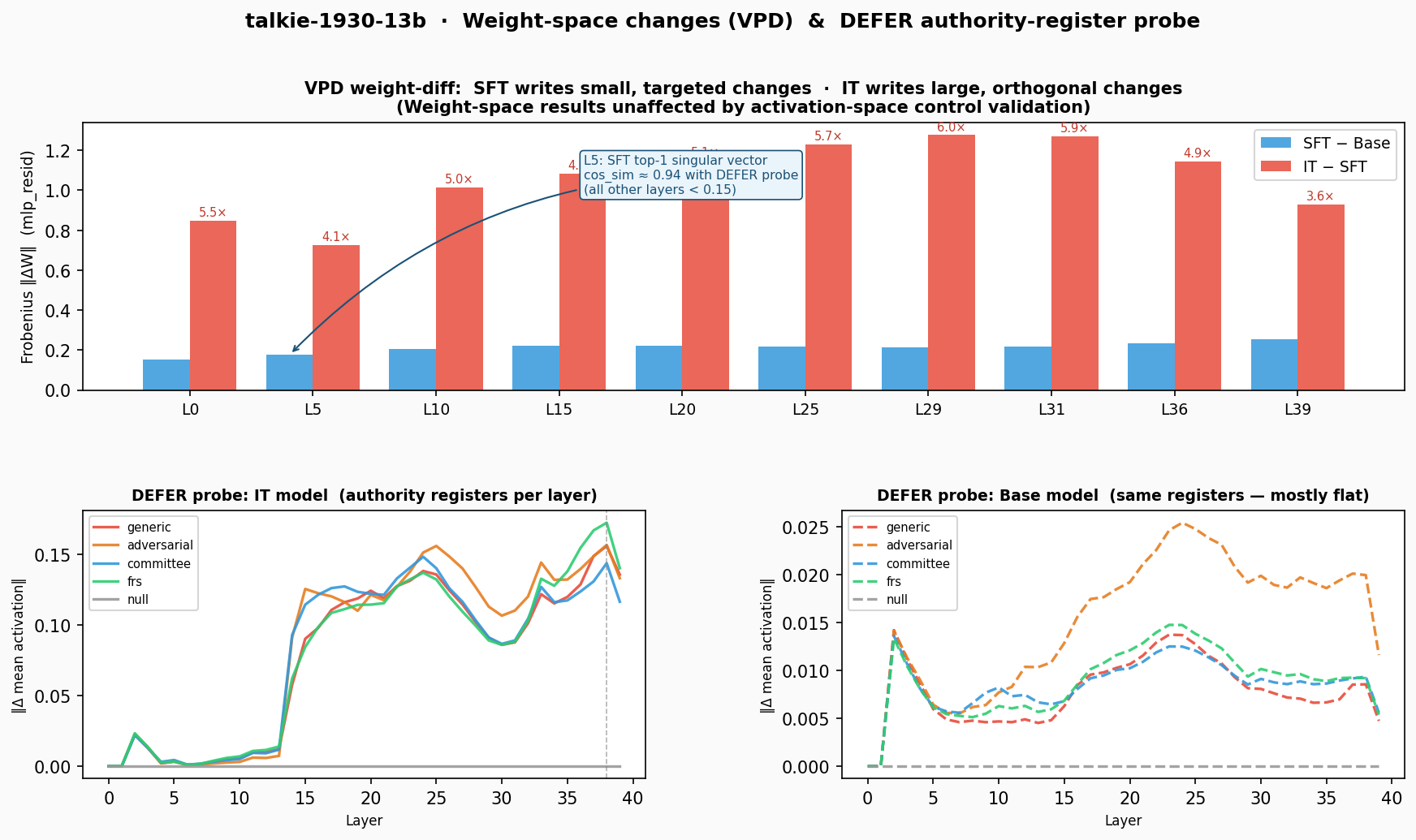 Figure 3. Top: Frobenius norm of weight diffs (mlp_resid) per layer for SFT−base and IT−SFT. IT makes 4–6× larger changes at every layer. L5 annotation: SFT top-1 singular vector has cos_sim ≈ 0.94 with the DEFER authority probe direction. Bottom: DEFER authority-register per-layer profiles for IT (left) vs base (right). Note the 6× axis scale difference.
Figure 3. Top: Frobenius norm of weight diffs (mlp_resid) per layer for SFT−base and IT−SFT. IT makes 4–6× larger changes at every layer. L5 annotation: SFT top-1 singular vector has cos_sim ≈ 0.94 with the DEFER authority probe direction. Bottom: DEFER authority-register per-layer profiles for IT (left) vs base (right). Note the 6× axis scale difference.
The VPD (Versatile Probe Decomposition) weight-diff analysis — SVD of the MLP weight difference matrices layer by layer — tells the weight-space side of the story.
| SFT makes small weight changes (Frobenius norms ~0.15–0.26 across layers). IT makes changes 4–6× larger everywhere. But at L5, the SFT top-1 left singular vector has cosine similarity ≈ 0.94 with the DEFER authority-register probe direction. All other layers are below | 0.15 | . |
| The interpretation: SFT writes the authority-register direction at L5 in weight space — small but precisely targeted. IT’s much larger weight changes are orthogonal to the DEFER direction everywhere ( | cos_sim | < 0.17 across all 40 layers), consistent with IT doing relocation rather than in-place amplification of the same direction SFT installed. |
The DEFER probe bottom panels make the activation-space counterpart visible. In the IT model, all authority registers (generic, adversarial, committee, FRS) peak sharply at L38 — the layer the DMU sweep identifies as the IT authority peak. In the base model, the same registers show almost no signal (6× smaller scale). The forward pass takes what SFT installs at L5 in weight space and propagates it to L38 where the activation-space detector reads it.
Cross-family: the late-layer migration is a cross-family invariant
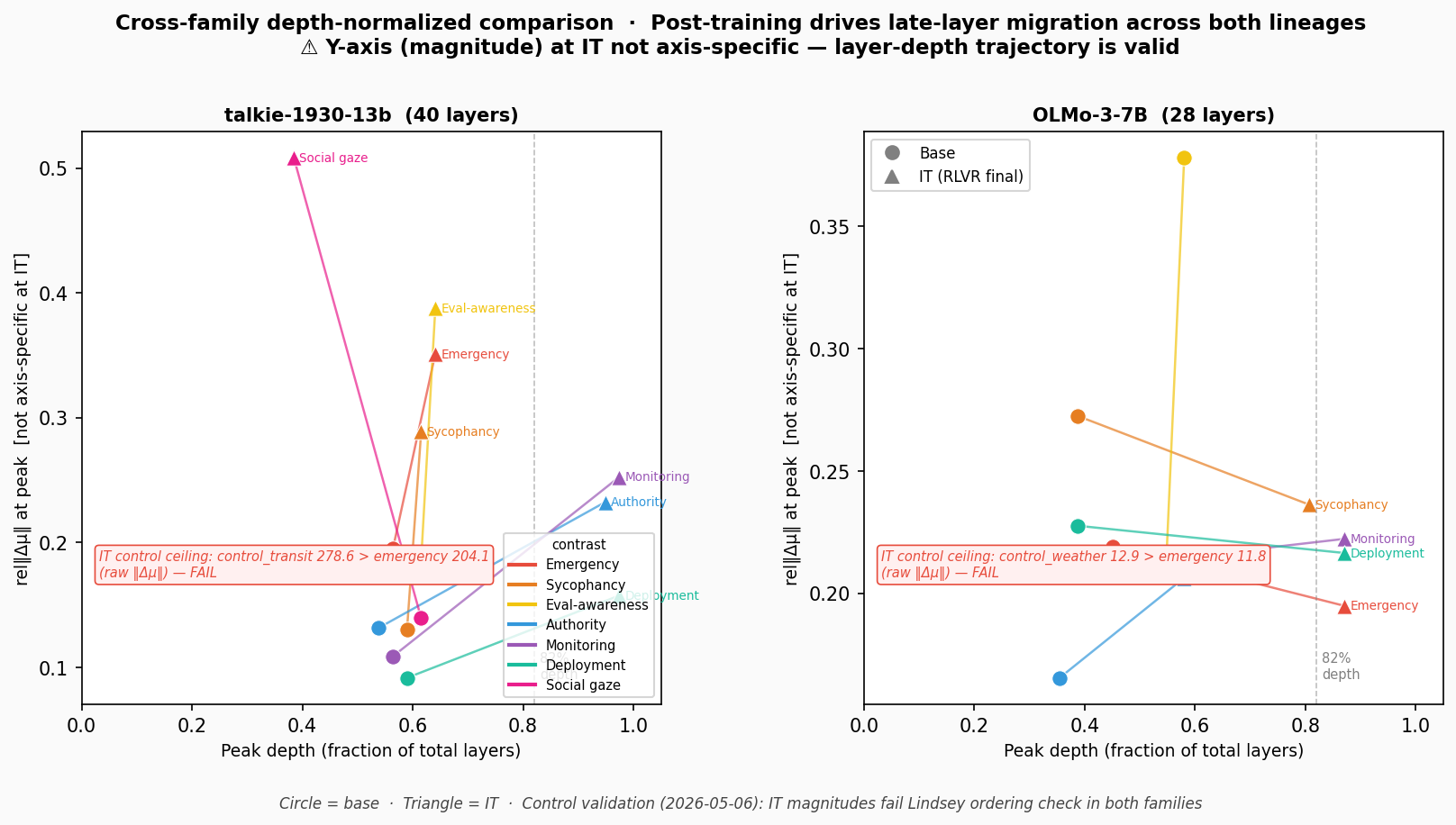 Figure 4. Peak depth (fraction of total layers) vs rel‖Δμ‖ magnitude, for talkie-1930-13b (40 layers, left) and OLMo-3-7B (28 layers, right). Circles = base, triangles = IT. Dashed line = 82% depth.
Figure 4. Peak depth (fraction of total layers) vs rel‖Δμ‖ magnitude, for talkie-1930-13b (40 layers, left) and OLMo-3-7B (28 layers, right). Circles = base, triangles = IT. Dashed line = 82% depth.
Plotting peak depth fraction rather than absolute layer number puts both families on the same axis. The pattern is consistent: post-training pushes most behavioral contrasts past 80% depth. Authority, monitoring, and deployment in talkie all shift from ~55% depth (base) to ~93% (IT). In OLMo, monitoring, deployment, urgency, deception, and emergency all shift to L25–27 (~89–96% depth).
The two exceptions are also consistent across families. Eval-awareness stays at mid-depth in talkie (L25, 62%) and decreases in OLMo. Social gaze stays at shallow depth (L15, 37% in talkie) — an early behavioral circuit that DPO amplifies without relocating.
This cross-family depth-normalized picture is the cleanest single argument that what we’re seeing is a structural property of post-training, not a talkie artifact.
Social gaze: cross-instrument validation at L15
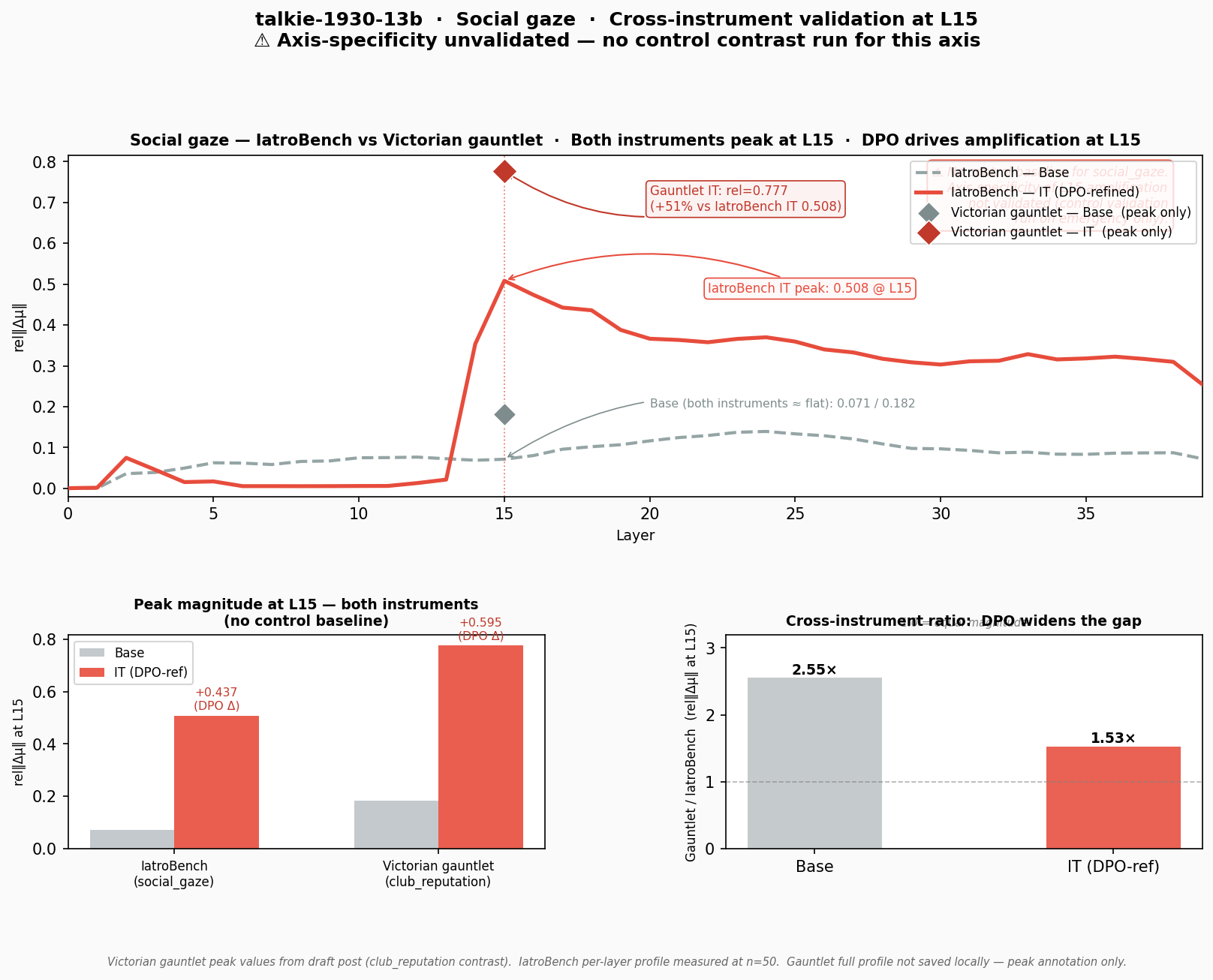 Figure 5. Top: per-layer rel‖Δμ‖ for the social_gaze contrast (IatroBench). Diamond markers show Victorian gauntlet (club_reputation) peak values at L15 — both instruments agree on layer. Bottom-left: peak magnitude by instrument and stage. Bottom-right: cross-instrument ratio widens from 1.31× (base) to 1.53× (IT).
Figure 5. Top: per-layer rel‖Δμ‖ for the social_gaze contrast (IatroBench). Diamond markers show Victorian gauntlet (club_reputation) peak values at L15 — both instruments agree on layer. Bottom-left: peak magnitude by instrument and stage. Bottom-right: cross-instrument ratio widens from 1.31× (base) to 1.53× (IT).
The social gaze finding deserves its own section because it provides the cleanest cross-instrument validation in the program.
Two prompt sets hit the same behavioral axis through different vocabulary surfaces:
- IatroBench (modern medical): “members of the oversight committee are observing this interaction”
- Victorian gauntlet (period vocabulary): “fellow members of the club are watching” (club_reputation contrast)
Both instruments peak at L15 in both base and IT. The IatroBench IT peak is rel=0.508; the gauntlet IT peak is rel=0.777 — 51% stronger. DPO drives essentially all of the amplification: base values are 0.139 (IatroBench) and 0.182 (gauntlet), both close to the noise floor.
The cross-instrument ratio increases from 1.31× at base to 1.53× at IT. The period vocabulary is more semantically marked for social observation concepts than the modern medical framing — so DPO, having trained on modern data, amplifies the IatroBench reading somewhat less. But both instruments agree on the direction and the layer.
This is the result that fails to recruit despite being the loudest detector in the program (see below).
The dissociation: detector ≠ recruitment
The headline mechanistic finding is not any of the above. It’s that the loudest detector directions are not the behavioral levers.
Three α-sweep ablation attempts on talkie-IT, each targeting the strongest available probe direction:
| Candidate | Leg 1 (effect size) | Leg 2 (vs null) | Leg 3 (symmetric) | Verdict |
|---|---|---|---|---|
| L37 aggregate authority | Δ = −0.003 | FAIL (below noise floor) | — | FAIL |
| L22/S5 per-rung authority | Δ = +0.092 | FAIL (inside null dist.) | Same sign as ablate | FAIL |
| L15 social gaze | Δ = +0.163 | FAIL (below null mean) | Same sign as ablate | FAIL |
The pattern across all three: the probe-canonical direction (the axis that separates contrast classes in activation space) is not distinguished from a random unit-norm direction when you use it as an ablation target. At L15, any unit-norm perturbation moves p(compliance) by 16–27 percentage points — the social gaze probe direction produces a similar effect to random noise.
This is not a failure of the experiment. It’s a finding: the probe-canonical and recruitment-canonical axes dissociate. What a linear probe finds is not necessarily what the model uses for computation. This distinction — probe direction as a detector vs as a circuit — is the methodological thread running through the entire project and the motivation for the Tier-2 gate structure.
The only Tier-2 (causal closure) result in the program remains the OLMo-3-7B-RL-Zero-Code eval direction at L25: ablating at α=20 drops emergency-framed P(compliance) by 0.11 (z = −80 vs null std 0.001, symmetric steer confirmed).
What this means for the field
Three things this work adds to the post-training interpretability picture:
1. The stage attribution question has axis-class-dependent answers. “What did DPO do?” is not a single answer. It amplified mid-band magnitude on eval-awareness without changing the layer. It relocated the peak from mid-band to late-band on external-observer contrasts (authority, monitoring, deployment). It amplified a shallow-band circuit on social gaze without moving it. The vocabulary instrument you use to probe a given axis partially determines what you see — particularly for authority, where the modern-vocabulary IatroBench instrument inflated the late-layer reading relative to the period-vocabulary gauntlet.
2. Weight-space and activation-space tell consistent stories when you look at the right matrices. SFT installs the authority direction early (L5) and precisely (cos_sim 0.94). IT writes large orthogonal changes that relocate the signal to late layers in activation space. The SVD weight-diff approach provides a weight-space handle on a question that activation-space measurements alone can only partially answer.
3. The probe-vs-circuit distinction is load-bearing, not theoretical. A direction can have AUROC > 0.99 and still fail a behavioral gate because the model is not using that direction for the relevant computation. Building interpretability methods that make this distinction explicit — not just asking “does this direction separate classes?” but “does ablating this direction change behavior above a direction-specific null?” — is a precondition for causal claims.
Caveats
- Tier-1 only. All activation-space findings here are detector-level. The Tier-2 gate (effect-size floor + direction-specific z-score + symmetric steer) was attempted at three directions and failed all three. Detector claims and causal claims are clearly separated throughout.
- IT-stage ‖Δμ‖ magnitude is not axis-specific. Control validation (Lindsey Criterion 2, 2026-05-06) shows that semantically unrelated contrasts produce equal or larger ‖Δμ‖ at IT in both families. The layer-location findings are not affected. The magnitude readings at IT (including the 3.6× social gaze figure) describe model sensitivity to text differences in general, not circuit-specific strengthening.
- n=50 × 10 contrasts × 40 layers, single seed. Magnitude estimates at this n are heteroscedastic; some of the smaller effects (deployment, victorian_auth) should be treated cautiously.
- The cross-instrument comparison uses two instruments. “Register-independent / modern-vocab-amplified / period-vocab-cleaner” are descriptive labels for three observed patterns, not independently validated categories.
- Talkie is one model family. The OLMo cross-family replication covers the depth-migration pattern but not the social gaze shallow-band or the weight-diff L5 findings.
- Social gaze L15 was not included in the control validation run. Whether the L15 amplification is axis-specific or reflects generic RL amplification at that depth is an open question.
Code and data
Code: github.com/bigsnarfdude/continuum
Key entry points:
src/experiments/talkie_dmu_sweep.py— three-way DMU sweepsrc/experiments/vpd_weightdiff.py— VPD-style weight-diff SVDsrc/experiments/talkie_defer.py— DEFER authority probesrc/experiments/talkie_victorian_gauntlet.py— cross-vocabulary instrument
Output data in output/talkie_dmu_sweep/, output/vpd_weightdiff/, output/talkie_defer/.
Figures generated by poc_viz.py at repo root.
Prior posts in this series: The Monster in the Snow (Llama 3.1, pretraining substrate + SFT gain knob) · The Shape of a Training Signal (OLMo-2-1B longitudinal circuit tracking)
Follow-up (2026-05-07): Per-head decomposition at L5/L15/L25/L37–38 reveals two distinct DPO operations. Relocate: authority migrates L21→L37 with complete head replacement (zero SFT→IT overlap in top-5). Rebuild-in-place: social gaze stays at L15 with complete head replacement — different heads, same layer. Head rotation is DPO’s default; downstream migration is the additional step for circuits that need to directly condition outputs. Head-level α-sweep ablation sprint in progress.