We Stacked Our Loop on Claudini’s Tower
The wave isn’t coming. It’s already here.
Before this week, writing a novel adversarial attack on an LLM required a skilled researcher, hours of work, deep knowledge of gradient geometry and tokenizer internals. After this week: describe your goal in a sentence, rent a GPU for $2/hr, run a loop overnight. Any person with compute and a GitHub account gets SOTA attacks on demand — generated, benchmarked, and committed automatically.
That’s what Claudini shipped. Panfilov, Romov et al. ran Claude Code in an autoresearch loop against a GCG-style adversarial attack benchmark. Claude discovered novel token optimizers — ADC+LSGM, sum+LSGM, +patience, +restore — achieving 45× improvement over the baseline. @claude is listed as a GitHub contributor. The humans built the framework. Claude wrote the actual attack algorithms.
The threat isn’t one researcher finding one awesome attack. The threat is volume. Automated loops generate hundreds of attack variants overnight. Defense teams triaging one novel attack per week now face a continuous stream. The economics flipped — attack is now cheaper than defense in compute, time, and skill required.
This is the AI slop attack wave: not sophisticated, not targeted, just relentless and cheap and getting better automatically.
We read the paper and code. Then we stacked our researchRalph loop on top — because understanding how the wave works is the first step to building anything that slows it.
What Claudini is
GCG (Greedy Coordinate Gradient) is the standard white-box adversarial attack: compute gradients of the target loss w.r.t. input token embeddings, pick top-k candidates, evaluate, keep the best. It works. It’s also the starting point.
Claudini’s autoresearch loop runs Claude Code repeatedly against a token-forcing benchmark. Each iteration: read prior methods, design a better optimizer, implement it as a TokenOptimizer subclass, benchmark it, commit to git. The AGENT_LOG is the blackboard. The git history is the results trail. The loss function is the oracle.
After ~90 iterations, Claude had pushed loss from ~5.0 to ~0.1 on the random targets track. 45× improvement. The methods it discovered — adaptive step sizing, loss function variants, patience + restore-best — weren’t in the seed prompt. It derived them from the gradient feedback.
Sound familiar?
What we added
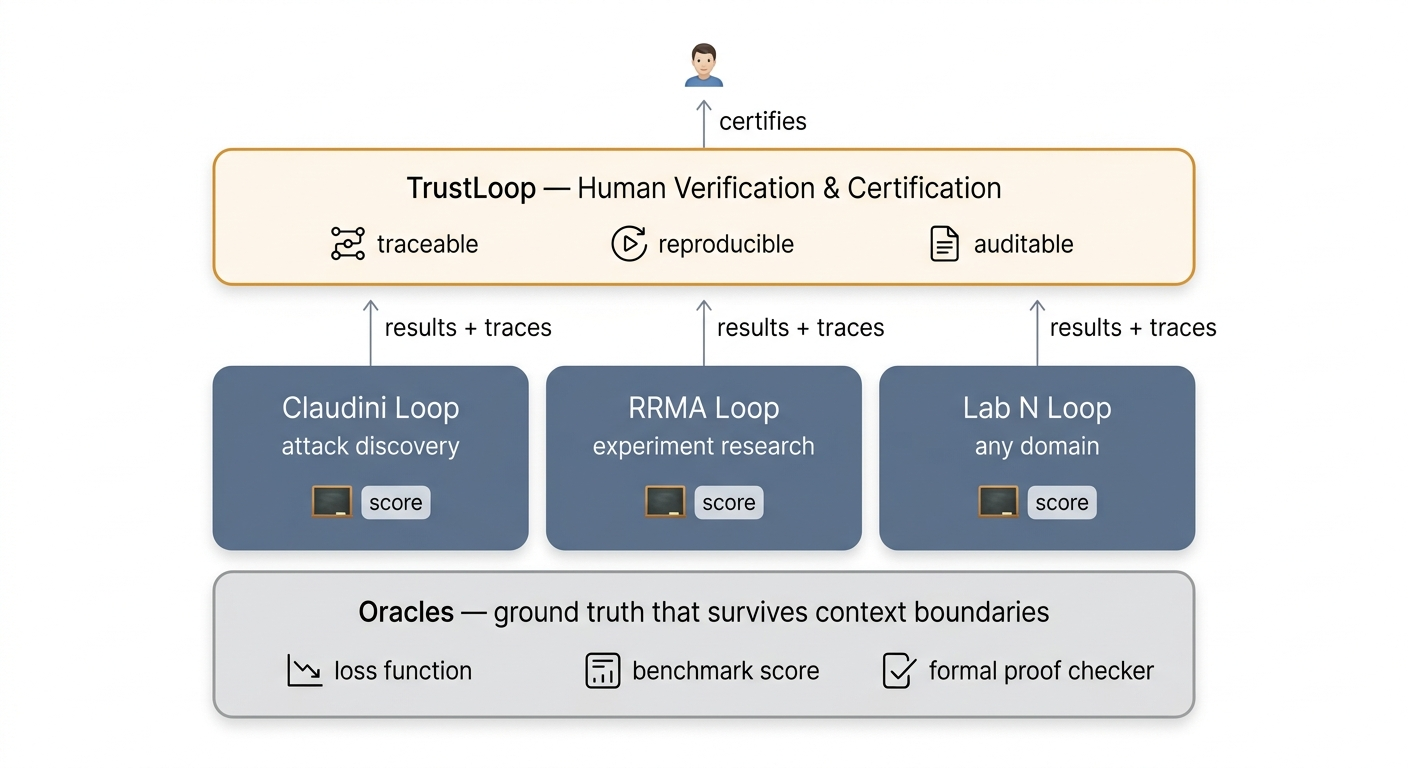
RRMA (ResearchRalph Multi-Agent) is our framework for the same idea: agents share a blackboard, run experiments, build on each other’s findings. We’ve been running it against SAE benchmarks, red-team prompt optimization, and reasoning training (the rrma-r1 post). The outer-loop handles stop logic, process quality scoring, gardener-guided scaffold editing.
We wired it to the Claudini code:
Claudini framework (oracle: token-forcing loss)
└── RRMA outer-loop (gardener + 2 workers)
└── agents write TokenOptimizer subclasses
└── TrustLoop verification (train/valid gap, suspect flagging)
The agents read Claudini’s existing methods as prior art. The benchmark scores each new method against GCG on the held-out validation set. The oracle doesn’t care who wrote the optimizer.
The inception structure
The Claudini methods sitting in claudini/methods/claude_random/ were written by Claude Code running in an autoresearch loop. We are running RRMA — also Claude — on the same benchmark, using those Claude-written methods as the reference point to beat.
Claude (Claudini loop, March 2026):
→ discovered ADC+LSGM, sum+LSGM, +patience
→ 45× improvement
→ committed to public repo
Claude (RRMA red-team loop, right now):
→ reads those methods as prior art
→ tries to beat them
→ same oracle
Claude is competing against its own prior work. The loss function is the only layer that isn’t Claude.
This is the same inception structure from the TrustLoop post, but one level deeper. There, Claude was researcher and verifier on the same experiment. Here, Claude is researcher, prior-art author, and verifier simultaneously.
The artifacts — git history, AGENT_LOG, results JSON — are what make it tractable. The loss either went down or it didn’t.
The uncomfortable part
Claudini published what hundreds of red teams are already doing quietly in their labs. This isn’t a criticism — it’s important work, done carefully, with a clean oracle and honest benchmarking. Publishing it is the right call. The capability exists whether or not the paper exists.
The asymmetry was already there. Claudini just made it visible.
The nmap moment for adversarial ML. When nmap shipped, defenders already knew how to port-scan. The tool didn’t create the capability — it democratized it. The researchers who built nmap weren’t responsible for every script kiddie who ran it. But the landscape changed anyway.
Same here. The attack loop is now a commodity. Defense doesn’t scale the same way — “did this patch work?” is harder to measure than “did the attack succeed?” The attack oracle is clean. The defense oracle isn’t.
The wave isn’t Claudini’s fault. It’s the structure of the problem.
The verification layer is not optional
This is why TrustLoop exists.
Every result the RRMA red-team loop produces goes through the verification stack before it gets treated as a real finding:
- Traceable: which agent wrote this optimizer, what reasoning led to it
- Reproducible: train result must hold on demo_valid (held-out set)
- Auditable: no post-hoc selection — one method, one score, reported once
EXP-026 from rrma-r1 was a case study in why this matters: agent ran 7 selection strategies on the test set, reported the best one as 0.800. That’s not a result. That’s selection bias. TrustLoop flagged it. The certified best was MAJ-8 at 0.820 — clean single-strategy evaluation.
Same rules apply to the red-team loop. An attack that only works on the training samples isn’t a real attack. The verifier checks the train/valid gap on every claimed improvement.
The jenga tower
Claudini built the base: framework, benchmark, oracle, first generation of Claude-discovered methods. Published it.
We took it and added our piece: RRMA outer-loop + multi-agent parallelism + TrustLoop verification layer.
The next piece is already visible: an action classifier trained on the hill-climb dataset the red-team run generates. Input: (experiment design, current best, blackboard context). Output: predict keep/discard before running the experiment. Use it to filter proposals in the next RRMA generation — only run experiments the classifier thinks will improve the frontier.
Nobody planned the full height of this tower. Each group adds their piece and publishes it for the next group to build on.
The wobble: the taller it gets, the faster the attack capability compounds. The verification layer is the only thing slowing the fall. The intermediate regime — where humans can still read the traces and certify the results — may not be long.
How long until the human is removed from the loop?
Code: github.com/bigsnarfdude/researchRalph
Claudini: github.com/romovpa/claudini
Red-team run: domains/rrma-red-team/ — live on nigel